Apache Kafka란
by jsh

Apache Kafka(아파치 카프카)
는 LinkedIn에서 개발된 분산 메시징 시스템으로써 2011년에 오픈소스로 공개되었다.
대용량의 실시간 로그처리에 특화된 아키텍처 설계를 통하여 기존 메시징 시스템보다 우수한 TPS(Transaction per Second)를 보여주고 있다.
Kafka 란?
- 분산 스트리밍 플랫폼
- 데이터 파이프 라인 구성 시 주로 사용되는 오픈소스 솔루션
- 대용량의 실시간 로그처리에 특화되어 있는 솔루션
- 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메시지 시스템
- 클러스터링이 가능하므로 Fault-Tolerant한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리
- 수평적으로 서버의 Scale-Out이 가능함
- pub-sub모델의 메시지 큐
데이터 파이프 라인: 데이터를 한 시스템에서 또다른 시스템으로 옮기는 작업을 뜻한다. Fault-Tolerant: 시스템 내 Fault(장애)가 발생하더라도 시스템에 지장을 주지 않도록 설계 된 컴퓨터 시스템 Scale-Out: 서버의 대수를 늘려서 성능을 향상시키는 방법
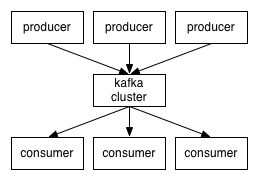
1. Pub-Sub 모델
- Pubish-Subscribe (발행/구독) 모델은 메시지를 특정 수신자에게 직접적으로 보내주는 시스템이 아님
- Publisher는 메시지를 Topic을 통해서 카테고리화 함
- 분류 된 메시지를 받기 원하는 Receiver는 그 해당 Topic을 구독(Subscribe)함으로써 메시지를 읽어 올 수 있음
- 즉, Publisher는 Topic에 대한 정보만 알고 있고 마찬가지로 Subscriber도 Topic만 바라봄
- 데이터를 관리하는 Kafka 서버를 사이에 끼고 데이터를 넣는 Publisher와 데이터를 읽는 Subscriber는 각자의 업무만 Kafka 서버를 통해 수행하므로 서로 모르는 상태
- Kafka Cluster를 중심으로 Producer가 데이터를 Push하고 Consumer가 데이터를 Pull하는 구조(Git Hub의 Push/Pull과 같은 과정)
2. Kafka 의 특징
- 메세지를 메모리에 저장하는 기존 메시징 시스템과는 달리 메시지를 파일 시스템에 저장
- 파일 시스템에 메시지를 저장하기 때문에 별도의 설정을 하지 않아도 데이터의 영속성(durability)이 보장됨.
- 디스크가 순차적으로 저장되어 있으므로 디스크 I/O가 줄어들어 속도가 빠름
3. Kafka 구조 및 구성요소
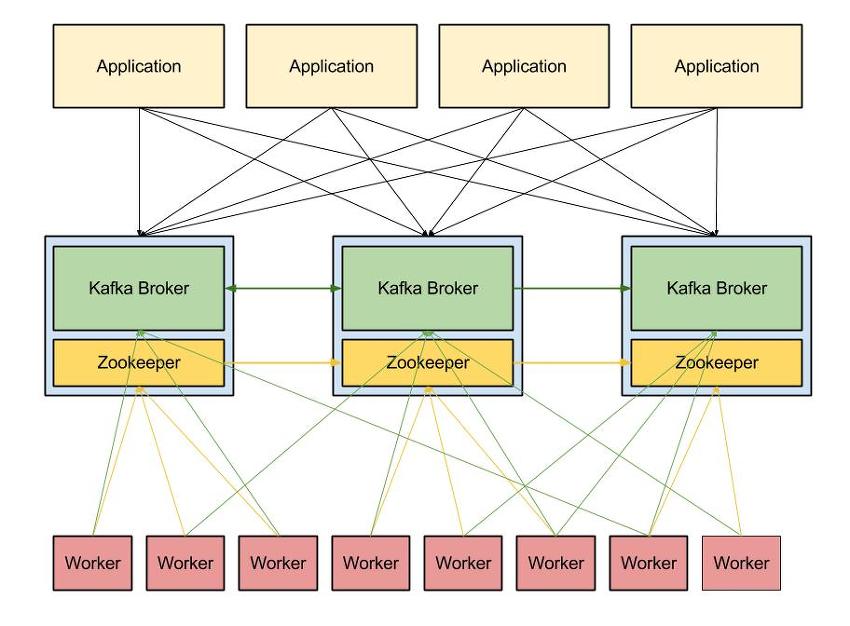
- 위의 그림에서 가운데 부분은 Kafka Broker와
Zookeeper
로 구성되어 있는데 Kafka Broker가 바로 Kafka서버이다.
Zookeeper는 Kafka Cluster를 구성할 수 있도록 분산 코디네이션 서비스(coordination service) 역할을 한다. - 위 그림에서 Kafka Broker와 Zookeeper로 구성되어 있는 것이 3개가 있는데 이것들을 묶어서 Kafka Cluster라고 부른다.
- Kafka Broker와 Zookeeper는 다른서버에 설치하여 운영하는 것을 추천하는데 이유는 만약 Zookeeper에서 시스템 오류가 발생한 경우 Kafka Broker에게 영향을 주지 않기 위해서이다.
- Kafka의 Topic은 Partition이라는 단위로 쪼개어져 Kafka Cluster의 각 서버들에 분산되어 저장된다.
- Partition에는 데이터들이 순차적으로 저장되며 Kafka서버는 해당 데이터를 설정 시간에 따라 보관한다.(Default: 7Day)
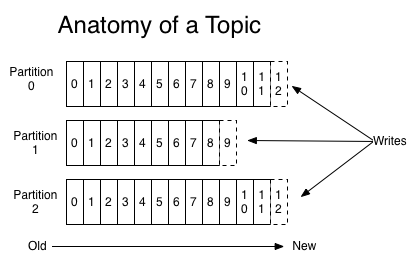
- 각 Partition은 0부터 1씩 증가하는 Offset값을 메시지에 부여하는데 각 Partition의 메세지를 식별하는 ID로 사용된다.
- Offset값을 Partition마다 별도로 관리되므로 Topic내에서 메시지를 식별 시 Partition 번호와 Offset 값을 함께 사용한다.
- 이러한 구조로 쓰여진 메시지는 해당 Topic을 구독(Subscribe)한 Consumer가 소비한다. Consumer가 가져다가 사용하는 구조이기 때문에 Consumer 스스로 소비하는 속도를 조절 할 수 있다.
- Consumer들의 묶음을 Consumer Group이라고 하는데 특정 Partition에는 Consumer Group당 오로지 하나의 Consumer만 접근이 가능하다.
즉 동일한 Consumer Group에 속하는 Consumer끼리는 동일한 Partition에 접근 할 수가 없다.
이때 특정 Partition에 접근하는 Consumer를 Partition Owner라고 한다. - Consumer가 메시지의 Offset 번호를 기억하고 있다가 다음 메시지를 읽어 올 때 Offset 번호를 이용해서 읽어 올 수 있다.
여기서 알아둬야 할 것은 하나의 Consumer Group 내부의 Consumer 끼리는 각자 접근하고 있는 Partition의 메시지 Offset 값을 공유하고 있어서 어떤 Consumer에서 장애가 발생하면 다른 Consumer가 장애가 발생 한 Consumer의 Offset값을 알고 있기 때문에 해당 Consumer 대신 메시지를 소비한다. - 한번 정해진 Partition Owner는 Kafka Broker나 Consumer 구성의 변동이 있지 않는 한 계속 유지된다.
- Consumer와 Partition의 대칭 비율은 1:N이며 Consumer가 Partition의 수 보다 많은 경우는 사용되지 않는 Consumer가 발생하고
Partition의 수가 Consumer의 수보다 많은 경우는 하나의 Consumer가 2개 이상의 Partition에 접근 할 수 있다.
그래서 Partiton과 Consumer의 수를 조절 할 필요가 있다.
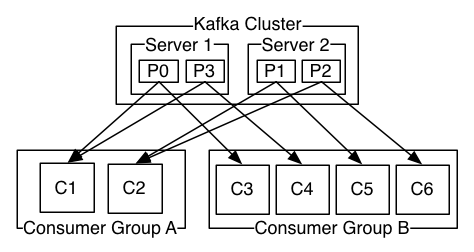
- 위의 그림과 같이 Consumer Group에 다수의 Consumer를 할당하면 각 Consumer마다 별도의 Partition으로부터 메시지를 받아오기 때문에 Consumer Group은 Queue 모델로 동작하게 된다.
- 하나의 Consumer로 이루어진 Consumer Group을 활용하면 다수의 Consumer가 동일한 Partition에 동시에 접근하여
동일한 메시지를 액세스하기 때문에 발행/구독(pub/sub) 모델을 구성 할 수 있다.
- 하나의 Consumer에 의하여 독점적으로 Partition이 액세스 되기 때문에 동일 Partition 내의 메시지는 Partition에 저장 된 순서대로 처리된다.
만약 특정 키를 지닌 메시지가 발생 시간 순으로 처리되어야 한다면 Partiton 분배 알고리즘을 적절하게 구현하여 특정 키를 지닌 메시지는 동일한 Partiton에 할당 되어 단일 Consumer에 의해 처리 되도록 해야 한다.
ex) 순서가 중요한 증권사 시스템 같은 경우 필요할 것으로 보임 - 다른 Partiton에 속한 메시지의 순차적 처리는 보장되지 않기 때문에 특정 Topic의 전체 메시지가 발생 시간순으로 처리되어야 할 경우 해당 Topic이 하나의 Partition만 가지도록 설정해야 한다.
- 하나의 Consumer에 의하여 독점적으로 Partition이 액세스 되기 때문에 동일 Partition 내의 메시지는 Partition에 저장 된 순서대로 처리된다.
- Kafka는 각각의 Kafka Broker에서 Topic들을 관리하는데 아래의 그림과 같이 하나의 Topic을 여러개의 Partiton으로 나누어서 각각의 Kafka Broker에 저장 할 수 있다.
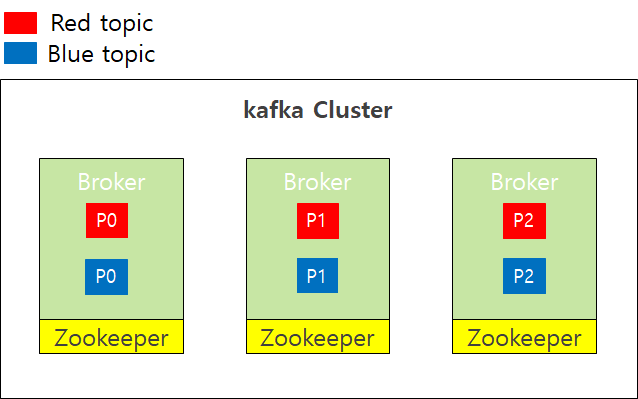
- Kafka는 여러 상황에 대비하여 Partition을 같은 Cluster안에 다른 Broker에 복사하여 저장 할 수 있는데
이때 필요한 것이 replication-factor 설정 값이다.
replication-factor는 간단히 말해 얼마만큼 Partition을 복사 할 것인지 설정하는 것이다. - 위에 그림과 같은 상황에서 replication-factor=3 값을 설정하게 되면 총 6개의 Partition이 각 서버에 3개씩 생기기 때문에 아래의 그림과 같이 총 18개의 Partition이 생기는 것이다.
- 여기서 알아둬야 할 것은 replication-factor는 Topic 단위의 설정 값이다.
ex) Red는 3, Blue는 2로 설정 가능
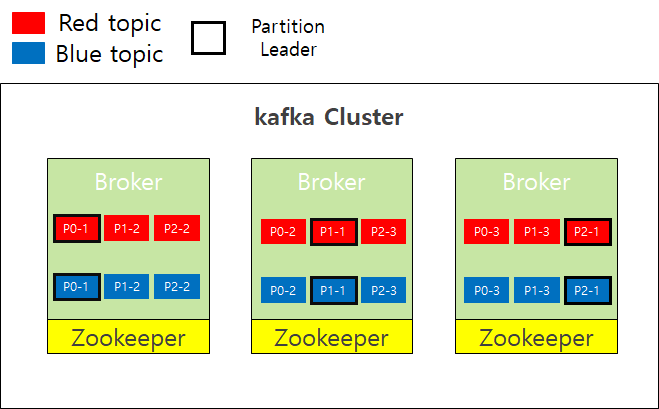
-
Red Topic
을 예로 설명하자면 첫번째 Broker에서 P0-1이 두번째 Broker에 P0-2로 복사 되었고 또 다시 세번째 Broker에 P0-3으로 복사 된 것이다.
이때 각 Partition들은 3개의 replica를 가진 것이다. - 여기서 주의깊게 볼 것은 검은 테두리로 씌워진 Partition인데 이 Partition이 바로 Leader이고 테두리가 씌워지지 않은 Partition은 Follower이다.
- 메시지를 Partition에 쓰고 읽는 행위는 Leader를 통해서만 수행할 수 있고 Follower는 Leader의 복사본 일 뿐 이다.
그렇다고 Follower가 해당 용도로만 사용되는 것은 아니다.
여기서 Leader와 Follower로 구성 된 것을 일컬어 ISR(In Sync Replica)라고 한다. - 만약 Leader에서 장애가 발생하였다면 해당 Partition을 복사한 Follower들 중 하나가 새로운 Leader가 된다.(Rebalancing)
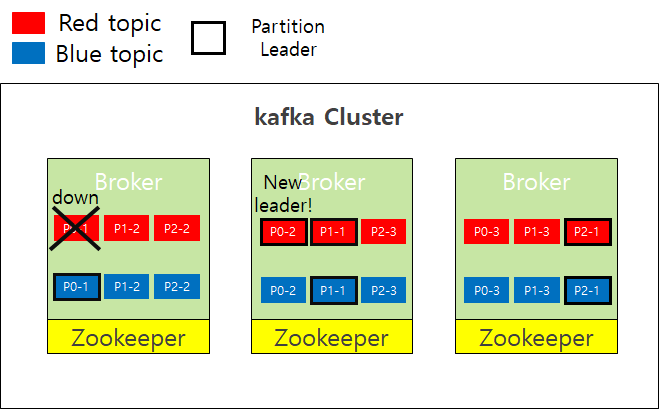
- 위와 같이 새로운 Leader가 선출되면 해당 Leader를 통해서만 메시지 읽기/쓰기가 가능하다.
Kafka Keyword 정리
-
Kafka Broker
: Kafka 서버
-
Zookeeper
: 분산 코디네이션 서비스(Kafka 서버 구성에 있어 필수)
-
Kafka Cluster
: (Kafka Broker + Zookeeper) x N
-
Producer(publisher)
: 데이터를 Kafka Cluster에 적재하는 주체
-
Consumer(Subscriber)
: Kafka Cluster로 부터 데이터를 읽어오는 주체
-
Consumer Group
: Consumer의 집합, Consumer x N
-
Topic
: Kafka Broker에서 사용하는 데이터(메시지)의 카테고리.
Partition의 집합.(Partition x N) -
Partition
: 메세지의 집합. Topic으로 묶여서 관리됨. Message x N
-
Offset
: Partititon마다 관리되는 메시지의 인덱스
-
Leader
: 메시지를 읽고 쓰는 것이 가능한 Partition
-
Follower
: Leader의 복제이며 잠재적 Leader
Subscribe via RSS